
데이터 마이닝 작동 방식
쇼핑할 때마다 흔적을 남깁니다. 마찬가지로 웹 서핑을 할 때 피트니스 트래커 (새 탭에서 열림) 를 착용하거나 은행에서 신용을 신청하세요. 사실, 우리가 그것을 만질 수 있다면, 우리는 그것을 익사시킬 것입니다. IBM (새 탭에서 열림) 에 따르면 우리가 매일 생산하는 데이터는 총 250경 바이트('25' 다음에 0이 17개 있음)라고 합니다. 우리는 현재 전 세계 데이터의 약 90%가 지난 2년 사이에 생성될 정도로 빠르게 생산하고 있습니다. 이 '빅 데이터'는 수십억 달러의 가치가 있는 글로벌 리소스이며 모든 기업과 정부가 이를 활용하기를 원합니다. 그럴 만한 이유가 있습니다.
데이터는 우리의 선택, 구매, 대화 상대, 가는 곳, 하는 일 등 일상 생활의 디지털 역사입니다. 우리는 이전에 사물 인터넷 (새 탭에서 열림) (IoT)과 '퍼베이시브 컴퓨팅'이 우리의 생활 방식을 근본적으로 바꾸는 방식을 살펴보았습니다. IoT로 인해 데이터 생성 및 캡처가 훨씬 더 폭발적으로 증가할 것이라고 확신할 수 있습니다. 클라우드 스토리지의 붐 덕분에 우리는 이미 가능한 한 빨리 이러한 것들을 치우고 있습니다.
그러나 데이터 자체는 꽤 쓸모가 없습니다. 데이터에서 추출한 정보는 가능한 테러 위협에 대해 정부에 미리 경고하고 다음 번에 지역 과일 및 채소에서 무엇을 살 가능성이 있는지 예측하는 데 필요한 모든 작업을 수행할 수 있습니다. 사용 가능한 엄청난 양의 데이터는 인간의 능력만으로는 해독할 수 없으며 이를 처리하기 위해 컴퓨터 처리가 필요합니다. 바로 여기서 '데이터 마이닝'이라는 개념이 등장합니다.
기계 학습

실제로 '데이터 마이닝'은 인공 지능(AI)의 파생물인 '머신 러닝'이라는 매혹적인 컴퓨팅 영역의 유행어입니다. 여기에서 컴퓨터는 특수 코드 기능 또는 '알고리즘'을 사용하여 산더미 같은 데이터를 처리하고 데이터로부터 정보를 생성하거나 '학습'합니다.
250년 이상 전에 처음으로 발견된 수학적 기술을 포함하는 선구적인 연구 분야가 현재 호황을 누리고 있습니다.
어떤 면에서 데이터 마이닝은 개인 정보 보호 및 데이터에서 마이닝된 정보가 사용되는 방식에 대한 윤리적 우려가 증가함에 따라 약간의 그림자가 드리워져 있습니다. 그러나 모든 '테러 플롯 및 쇼핑 카트'는 아닙니다. 데이터 마이닝은 일기 예보에서 의학 연구에 이르기까지 모든 분야에서 과학에서 많이 사용되며, 유방암 재발을 예측하고 당뇨병 발병 지표를 찾는 데 사용되었습니다.
Stanford University의 Folding@Home (새 탭에서 열림) 질병 연구 프로젝트는 암, 파킨슨병 및 알츠하이머병에 대한 치료법을 찾기 위해 참여할 수 있는 전 세계적 규모의 데이터 마이닝입니다.
본질적으로 머신 러닝은 데이터에서 패턴을 찾고, 의사 결정 및 예측을 할 수 있게 해주는 '규칙'을 학습하거나, 상황이나 애플리케이션의 요인 간의 연결 또는 '연관성'을 찾는 것입니다.
무료 소프트웨어 받기
이제 머신 러닝이 컴퓨터 뱅크, 산더미 같은 클라우드 스토리지, 고가의 전용 소프트웨어가 있는 실험실에서 수행된다고 생각할 수 있습니다. 맞겠지만 집에서도 할 수 있는 일이기도 합니다. 게다가 상당량의 기계 학습 소프트웨어를 무료로 사용할 수 있습니다. 'Hadoop' 또는 'R'과 같은 인기 있는 예는 산더미 같은 데이터를 처리하기 위한 강력한 프레임워크를 제공하지만 처음 사용하는 경우 다소 어려울 수 있습니다. 그리고 Holden 대 Ford 또는 Android 대 iOS처럼 서로 다른 소프트웨어를 열정적으로 지지하는 분야입니다.
기초 학습에 일반적으로 사용되는 앱 중 하나는 뉴질랜드 와이카토 대학에서 개발한 WEKA (새 탭에서 열기) 입니다. Hadoop과 마찬가지로 Java 프로그래밍 언어를 사용하여 구축되었으므로 모든 Windows, Linux 또는 Mac OS X 컴퓨터에서 실행할 수 있습니다. 완벽하지는 않지만 그래픽 사용자 인터페이스(GUI)가 확실히 도움이 됩니다.
기계 학습 작동 방식

기계 학습은 학습하려는 상황을 나타내는 '데이터 세트'로 시작합니다. 이를 스프레드시트로 생각하면 됩니다. 열에는 일련의 측정 또는 '속성'이 있으며 각 행은 학습하려는 사물 또는 '개념'의 예 또는 '인스턴스'를 나타냅니다.
예를 들어 당뇨병 발병 지표를 찾는 경우 이러한 속성에는 환자의 체질량 지수(BMI), 혈당 수치 및 기타 의학적 요인이 포함될 수 있습니다. 각 인스턴스에는 한 환자의 속성 집합이 포함됩니다. 이 상황에서 데이터 세트에는 환자가 당뇨병을 앓았는지 여부를 나타내는 결과 또는 '클래스' 속성도 있습니다.
다른 환자가 진단을 위해 내원하고 우리가 그들이 당뇨병의 위험이 있는지 알고 싶다면 기계 학습은 데이터 세트 학습과 그 사람의 측정된 의료 속성을 기반으로 그 가능성을 예측하는 데 도움이 되는 규칙을 개발할 수 있습니다.
규칙은 어떻게 생겼습니까?
TechRadar에서 우리가 정말 좋아하는 도구 중 하나는 소셜 네트워크 서비스를 결합하여 연결된 기능을 수행하는 프로그램인 IFTTT (새 탭에서 열림) (If This Then That)입니다. 이름에서 알 수 있듯이 '만약 이벤트가 발생하면 무언가를 하십시오'라는 간단한 'if-then' 프로그래밍 문에서 작동합니다.
기계 학습의 기본 규칙은 동일합니다. 이벤트 X가 발생하면 결과는 Y입니다. 또는 일련의 이벤트가 될 수 있습니다. X, Y 및 Z가 발생하면 결과는 A 또는 A, B 및 C입니다. .
이러한 규칙은 우리가 배우고자 하는 개념에 대해 알려줍니다. 그러나 규칙이 우리에게 알려주는 것만큼 중요한 것은 규칙이 얼마나 정확한가 하는 것입니다. 규칙 정확도는 올바른 결과를 제공하기 위해 규칙에 얼마나 많은 확신을 가질 수 있는지를 나타냅니다.
일부 규칙은 훌륭합니다. 매번 올바른 답을 얻을 수 있고, 다른 규칙은 절망적일 수 있으며, 일부는 중간에 있을 수 있습니다. 또한 복잡한 문제가 추가되었습니다. '과적합'이라고 하는 규칙 세트는 학습한 데이터 세트에서 완벽하게 작동하지만 제공된 새로운 예제나 인스턴스에서는 성능이 좋지 않습니다. 머신 러닝과 이를 사용하는 데이터 과학자가 고려해야 할 모든 사항입니다.
기본 알고리즘
수십 가지의 다양한 기계 학습 기능 또는 '알고리즘'이 있으며 그 중 다수는 매우 복잡합니다. 하지만 'ZeroR'과 'OneR'이라는 두 가지 간단한 예제를 빠르게 배울 수 있습니다. WEKA 앱을 사용하여 표시할 뿐만 아니라 작동 방식을 확인하기 위해 직접 계산할 수도 있습니다.
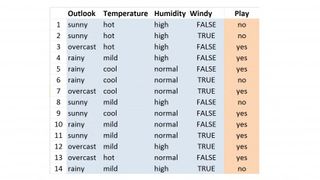
WEKA 패키지에는 다수의 예시 데이터세트가 포함되어 있는데, 그 중 하나는 매우 작은 'weather.nominal' 데이터세트로, 해당 시점에 일련의 날씨 이벤트가 주어졌을 때 특정 날짜에 골프가 치러지는지 여부에 대한 14개의 인스턴스가 포함되어 있습니다. 전망, 온도, 습도, 바람, 놀이의 다섯 가지 측정 또는 '속성'이 있습니다. 이 마지막 항목은 출력 또는 'class' 속성으로, 그날 골프를 쳤는지(yes) 아닌지(no)를 나타냅니다.
제로화
ZeroR은 세계에서 가장 간단한 데이터 마이닝 알고리즘입니다. 너무 간단하기 때문에 '알고리즘'이라고 부르는 것은 다소 무례하지만 적절한 알고리즘이 구축되기를 바라는 기본 정확도 수준을 제공합니다.
다음과 같이 작동합니다. 위 이미지에서 날씨 데이터를 확인하고 'play' 클래스 속성을 보고 'yes' 및 'no' 값의 수를 세십시오. 9개의 '예' 값과 5개의 '아니오' 값을 찾아야 합니다. '예' 값의 비율은 14개 인스턴스 중 9개입니다. 즉, 다른 인스턴스를 얻고 골프를 할 것인지 여부를 예측하려는 경우 '예'라고 말하면 14번 중 9번 또는 64.2%의 확률로 맞을 수 있습니다. 즉, ZeroR은 단순히 가장 인기 있는 클래스 속성 값을 선택합니다.
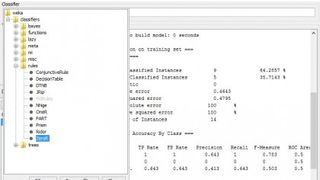
WEKA에서 이를 테스트할 수 있습니다. PC에 JRE(Java Run-time Engine)가 설치되어 있는지 확인한 다음 WEKA를 다운로드하고 설치하고 앱을 실행하십시오. 학습 창을 시작하려면 '탐색기' 아이콘을 클릭하십시오. WEKA는 ARFF라는 수정된 CSV(쉼표로 구분된 변수) 형식을 사용하며 /program files/weka-3-x/data 하위 폴더에서 예제 데이터 세트를 찾을 수 있습니다. 탐색기 창에서 파일 열기 버튼을 클릭하고 'weather.nominal' 데이터셋을 선택합니다. 다음으로 분류 탭을 클릭하면 선택 버튼 옆의 분류자 텍스트 상자에 'ZeroR'이 이미 표시되어 있어야 합니다. 왼쪽 컨트롤 패널의 '테스트 옵션'에서 '트레이닝 세트 사용' 옆의 라디오 버튼을 클릭하고 마지막으로 시작 버튼을 누릅니다.
거의 즉시 분류자 출력 창에서 결과를 얻을 수 있습니다. 아래로 스크롤하면 ZeroR이 'yes' 클래스 값을 선택하고 나중에 '9' 및 '64.2857%'를 옆에 표시하는 'Correctly Classified Instances'를 선택하는 것을 볼 수 있습니다. 요컨대, WEKA는 이전에 했던 것과 동일한 작업을 수행했습니다. '예' 및 '아니오' 클래스 값을 세고 가장 일반적인 것을 선택했습니다.
그들 모두를 지배하는 하나의 규칙
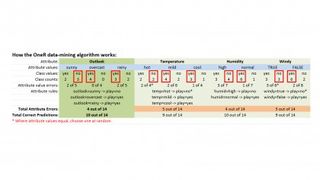
ZeroR은 이 예에서 64.2%의 기본 수준 학습 정확도를 제공하지만 그보다 조금 더 잘하면 좋을 것입니다. 그것이 바로 OneR 알고리즘이 들어오는 곳입니다. 학습 데이터 세트에서 학습한 내용을 바탕으로 미래 인스턴스의 결과를 결정하거나 '분류'할 수 있는 규칙을 생성한다는 점에서 '분류 규칙 학습기'라고 합니다.
위의 OneR 테이블을 보면 어떻게 작동하는지 알 수 있습니다. 각 날씨 데이터 세트 속성에는 가능한 값이 적습니다. Outlook의 경우 '맑음', '흐림' 및 '비'입니다. 온도는 '덥다', '온화하다', '시원하다' 등입니다. 각 속성 값에 대해 별도의 목록을 만든 다음 '예' 및 '아니요' 결과의 수를 기록하여 인스턴스에서 각 값이 발생하는 횟수를 계산합니다.
예를 들어 14개의 인스턴스를 살펴보면 전망이 밝은 5개의 인스턴스를 볼 수 있으며 2개의 '예'와 3개의 '아니오' 결과를 제공합니다. 마찬가지로 'outlook = overcast'는 4개의 '예' 투표와 0개의 '아니오' 결과를 얻습니다. 그런 다음 다른 모든 속성에 대해서도 마찬가지로 수행합니다.
다음으로 오류 수를 세었습니다. 이는 각 속성 값에 대한 더 작은 수이므로 'outlook = sunny'의 경우 '예' 수는 단 2개입니다. '전망 = 흐림'의 경우 '아니요' 개수는 0이고, '전망 = 비'의 경우 2입니다. 테이블의 빨간색 상자는 각 속성 값에 대해 가장 많이 사용되는 클래스 값을 표시하며 이로부터 첫 번째 'Outlook' 규칙 집합을 만듭니다.
Outlook = 맑음 -> 재생 = 아니요 Outlook = 흐림 -> 재생 = 예 Outlook = 비 -> 재생 = 아니요
다시 말하지만 다른 속성에 대해서도 마찬가지입니다. 우리가 하는 일은 각 속성 값에 대해 가장 인기 있는 클래스 값을 가져와서 해당 속성-값 쌍에 할당하여 규칙을 만드는 것입니다. 따라서 이 예의 경우 전망이 '맑음'이면 플레이가 '아니오'가 되는 식입니다. . 다음으로 다른 세 가지 속성 각각에 대해 이 작업을 반복합니다. 그런 다음 각 속성 값에 대한 '오류' 수를 합산하므로 Outlook은 2 + 0 + 2로 총 14개 중 4개(4/14)입니다. 온도의 경우 습도의 경우 5/14, 4/14, 바람의 경우 5/14를 얻습니다.
이제 오류 수가 가장 적은 속성을 선택합니다. 이 예에서는 오류 수가 14개 중 4개(Outlook 및 Humidity)인 두 가지 특성이 있으므로 둘 중 하나를 선택할 수 있습니다. 첫 번째 특성인 위의 'Outlook' 특성 규칙 집합을 사용했습니다.
이것은 이제 'OneR'(하나의 규칙) 분류 규칙 세트가 됩니다. 교육 데이터 세트에서 이 규칙을 사용하여 14개 인스턴스 중 10개 또는 71.5%에 약간 못 미치는 것을 정확하게 예측합니다. ZeroR은 64.2%를 제공하므로 OneR은 우리가 원하는 더 큰 정확도를 얻습니다.
새 규칙 사용
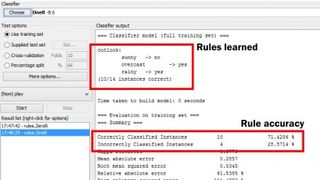
우리에게 새로운 사례가 주어졌다고 가정해 보겠습니다. 전망은 비가 오고 온도는 온화하며 습도는 높고 바람이 많이 부는 것은 잘못된 것입니다. '플레이'란 무엇인가 – 골프를 할 것인가 말 것인가? OneR 규칙에 따르면 전망이 좋지 않으면 플레이는 '아니오'이므로 이것이 우리의 대답입니다. 이 경우 오늘 골프가 없을 가능성이 매우 높습니다(약 71.5%).
선택 버튼을 클릭하고 '규칙' 목록에서 'OneR'을 선택하여 WEKA에서 OneR 분류 테스트를 실행합니다. 시작 버튼을 누르면 동일한 규칙 목록, 올바르게 분류된 인스턴스의 수는 10개, 백분율은 71.4286개로 표시됩니다. 이전에 계산했던 것과 정확히 일치합니다.
빙산의 일각
물론 우리는 날씨 이벤트를 기반으로 골프를 칠 날을 예측하여 수백만 달러를 벌거나 세상을 구하지는 않을 것입니다. 여기에서 본 것보다 훨씬 더 복잡함) 이러한 답변에 도움이 될 수 있습니다.
기계 학습은 우리를 둘러싼 정보의 '데이터에 의한 죽음' 과부하를 이해하는 것을 목표로 하는 전 세계 컴퓨터 연구의 붐 영역입니다. 우리는 여기에서 표면을 거의 긁지 않았지만 다음에 인터넷을 사용하거나 쇼핑을 할 때 우리가 생성하는 데이터에 어떤 일이 발생하는지 더 잘 알 수 있기를 바랍니다.